
| Home | Syllabus | Schedule | Lecture Notes | Extras | Glossary |
| Home | Syllabus | Schedule | Lecture Notes | Extras | Glossary |
We began with a review of the end of the last lecture, in which we looked a the early thoughts from the late 1950s on the nature of the genetic code. We saw last time that if the genetic code were one base, we could only encode four different amino acids. With a two base genetic code, we can encode 42 or 16 amino acids, which is not enough to encode the 20 primary amino acids.
With a three base genetic code, we can encode 43 or 64 amino acids, which is more than enough to encode the 20 primary amino acids. We can speculate that it is likely that the genetic code is degenerate, that is to say, that some amino acids are encoded by multiple three-base synonyms.
In the early days of thinking about the genetic code, it seemed possible that the code was overlapping. Overlapping and nonoverlapping genetic codes are compared in the figure below.
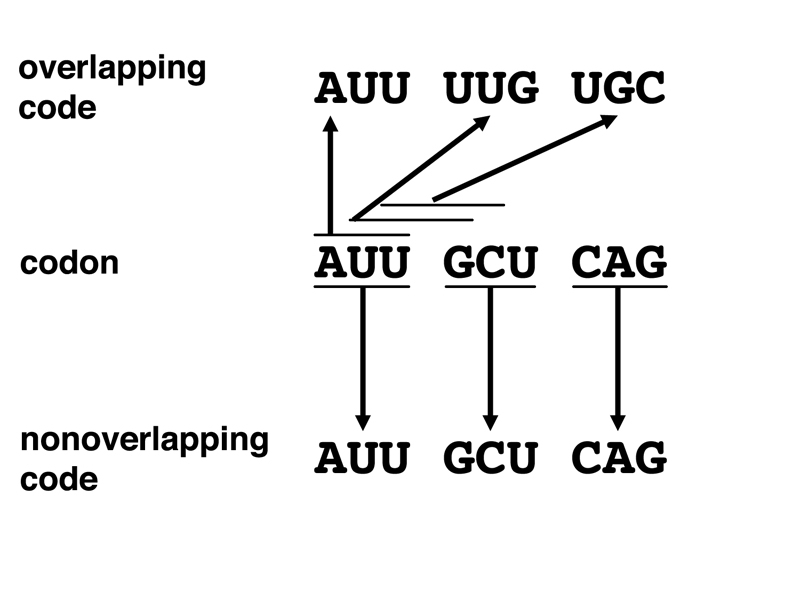
In a nonoverlapping code, bases are read three at a time. Each triplet codon stands for a particular amino acid. A triplet of bases is read to specify a particular amino acid. Then the next triplet is read to specify the next amino acid, and so on.
In an overlapping code, bases are read three at a time, but the last two bases of the prior codon are the first two bases of the next codon. It is immediately apparent that an overlapping code would have restrictions on which amino acids might be adjacent in all the possible proteins that might be encoded. In 1957, chemical sequencing of proteins had been worked out, and there was enough data on protein sequences to conduct nearest-neighbor analysis to search for forbidden neighbors.
A student argued that it might be possible to assign amino acids to codons in such a way that no particular nearest-neighbor pairs were forbidden. My intuition was that it was very likely that any assignment of amino acids to codons would be likely to generate nearest-neighbor restrictions. It is not essential to complete this argument, as there is another line of evidence that shows that the code is nonoverlapping.
Chemical mutagenesis of Tobacco Mosaic Virus (TMV) showed that it was possible to generate mutations in the major protein of TMV that only altered a single amino acid. If the code were overlapping, single amino acid substitutions should not occur; one or both adjacent amino acids should change in chemically-induced mutations as well.
We can see that the code only needs to be a triplet code to allow all 20 primary amino acids to be encoded. What is the evidence that a triplet code is actually used?
The first evidence comes from work by Francis Crick, Sydney Brenner, and their colleagues in 1961. They were working with bacteriophage T4, a phage not unlike T2, which we first met in connection with the Hershey-Chase experiment. There are "rapid lysis" mutants of T4 that produce clear plaques rather than the turbid plaques of normal T4. One class of such mutations occurs in a gene called rII. The rII mutant phage are unable to grow on E. coli strain K, although they can be grown on strain B.
It is possible to use a variety of different mutagens to generate rII alleles. One mutagen that produced interesting results was proflavin, an acridine. This compound looks very much like a DNA base pair, and is able to intercalate into DNA. Proflavin causes errors in DNA replication, producing variants that have added or deleted a base. This story starts with a proflavin-induced rII allele called FC0. This mutant, like all rII mutants, is unable to grow on strain K.
When FC0 was grown on strain B in the presence of proflavin and then plated on strain K, a number of revertants were obtained. These are actually pseudorevertants rather than wild type. It is possible to cross phage by coinfecting a permissive strain with two genetically distinct phage. When FC0 pseudorevertants were crossed to wild type and plated on strain B, many rII plaques are obtained, far higher than the mutation rate. Some of these rII plaques are FC0, others are a new allele. Apparently, a second mutation in the rII gene is capable of suppressing FC0.
Let's call the suppressor of FC0 "m1". This is an rII allele on its own, and it is possible to isolate proflavin-induced pseudorevertants of this allele also. Soon, we have amassed a collection of proflavin-induced rII mutants and their suppressors. Without getting into all the details of phage genetics, it is possible to construct double and triple mutant phage. Crick and Brenner arbitrarily designated FC0 as "+" and suppressors of FC0 as "-." Making double and triple mutant phage produces the results shown below.
| Mutations | rII phenotype |
| FC0(+) | mutant |
| FC0(+) m1(-) | normal |
| m1(-) | mutant |
| m1(-) m2(+) | normal |
| FC0(+) m2(+) m3(+) | normal |
| m1(-) m4(-) m5(-) | normal |
The results show that a mutation designated "+" is suppressed by one designated as "-". Combinations of two "+" mutations or two "-" mutations are still mutant, but combining three "+" or three "-" mutations produces wild type.
If the proflavin-induced rII mutations are insertions or deletions of a single base in the rII gene, these are the results that we would expect from a nonoverlapping triplet code with no punctuation between the codons. Insertion or deletion of a single base causes the reading frame to shift, producing a nonfunctional protein. A mutation that is an insertion of a base might be suppressed by a nearby deletion of a base. The sequence between the mutations will be out of frame, but downstream of the second mutation, the reading frame will be correct, and protein function will be restored. Combinations of three plus or three minus alleles will have the incorrect protein sequence between the first and third mutations, but downstream of the third mutation, the protein sequence will be correct.
The experiments that we have described so far show that the genetic code is nonoverlapping, is based on triplets, and has no punctuation other than start and stop (no commas or slashes between codons).
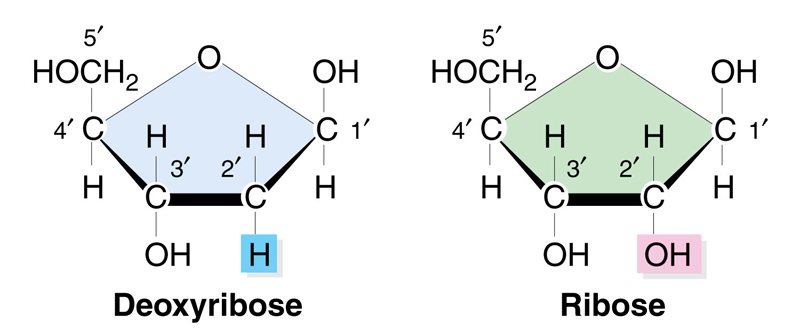
At this point, it is necessary to review the structure of RNA, which is very similar to the structure of DNA. The first difference is that RNA has ribose as the sugar, while DNA has deoxyribose. The structure of the two sugars is shown below; deoxyribose has no hydroxyl on the 2' carbon. The sugars are otherwise the same.
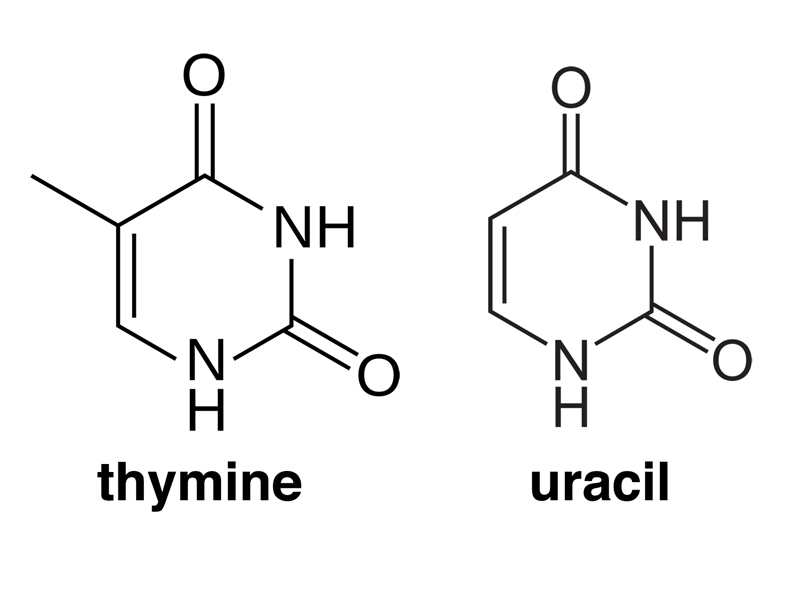
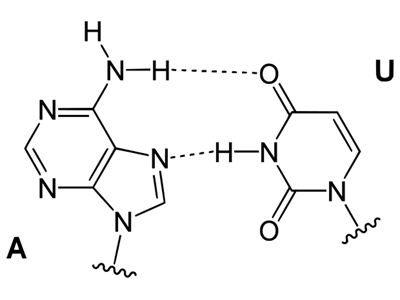
The next difference is that RNA has uracil (U) as a base instead of thymine (T). The structures of the two bases are shown below. Note that thymine has a methyl group in one position that uracil lacks. This is the only difference between the two bases.
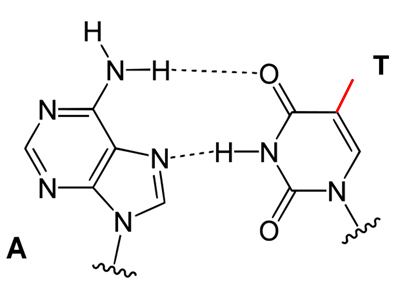
In the drawings below, you can see that the differnce between thymine and uracil does not affect base pairing.
 |
 |
Crick's original statement of the Central Dogma was that information flowed from nucleic acids to proteins. What is the evidence that there is an RNA intermediate between DNA and protein?
One type of evidence comes from pulse-chase experiments. I introduced the concept on a global scale with a long time frame by discussing the meltdown of the Fukushima nuclear plant in Japan following a tsunami. This released a large quantity of radioactive material into the Pacific Ocean off the coast of Japan. If we imagine that the leak was promptly stopped (there is still leakage, but let's pretend), there will be a plume of radioactive material from the time of the accident that can be used to track ocean currents.
On a smaller scale, we can imagine giving eukaryotic cells a pulse of labeled uracil for perhaps five minutes, following this by fresh medium containing a vast excess of unlabelled uracil. We can then take samples and fractionate cells, or perhaps use in situ hybridization to locate the label microscopically.
In such an experiment, the first parts of the cell to be labeled at time zero, when we add the chase, would be the nucleus. Over time, radioactivity will move to the cytoplasm until the nucleus is free of radioactivity. Because we have labeled uracil, we know that we are following RNA, which is synthesized in the nucleus before it moves to the cytoplasm.
If we were to label protein with radioactive leucine in a puls-chase experiment, we would first see label in the cytoplasm, where protein is synthesized. Over time we might see some in the nucleus (which contains a lot of protein) as well as in the cytoplasm, the plasma membrance, and outside the cell.
Experiments of this kind show that RNA is synthesized in the nucleus, where the DNA is. It moves to the cytoplasm, the site of protein synthesis. DNA doesn't move, so RNA must be the intermediate between DNA and protein.
When we compare DNA and RNA, we can see that DNA is archival, while RNA is a working copy of the genetic information. DNA replication has a very low error rate, due to the low intrinsic error rate of DNA polymerase, the 3' to 5' exonuclease function of DNA polymerase that proofreads newly synthesized DNA, and the mismatch repair system, which fixes errors. Finally, in eukaryotes, DNA stays in the nucleus while RNA moves to the cytoplasm.
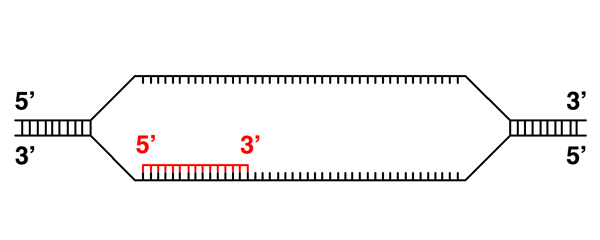
Because DNA and RNA have similar structures, and we know that we can form DNA-RNA hybrids (for example, in the synthesis of RNA primers during DNA replication), the basic mechanism of transcription is obvious: it will resemble DNA replication, except that the newly-synthesized strand will be RNA. The process is illustrated and described below.
 |
Transcription requires the opening of the DNA helix, similar to replication. |
 |
An RNA transcript is synthesized in the 5' to 3' direction, just like a new strand of DNA. This makes sense, as we saw during our discussion of DNA replication, because elongation of a nucleic acid strand from the 5' to 3' direction derives the required energy from dNTPs or NTPs, while elongation from the 3' to 5' direction would place the high-energy triphosphate on the end of the elongating strand. As the phosphate bond can spontaneously hydrolyze, elongation from the 3' to 5' direction risks chain termination. |
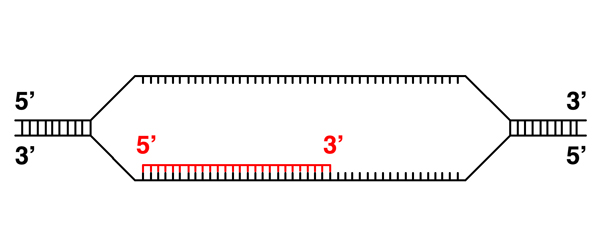 |
Here the RNA transcript continues elongation. |
 |
The transcript is complete. |
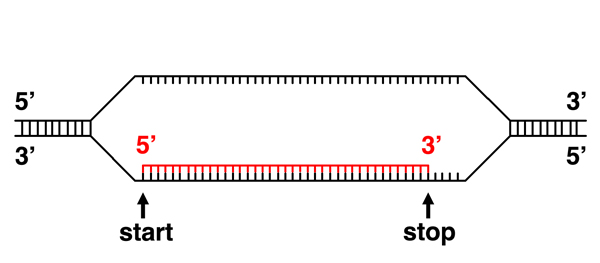 |
Initiation of transcription at a specific site at the beginning of a gene implies that there is a signal in the DNA sequence that indicates a transcription start site. Similarly, the termination of transcription at a specific site at the end of a gene implies that there is a signal in the DNA sequence that indicates a transcription termination site. In addition, it is clear that the transcription machinery must be able to read these signals, which implies that proteins can read the sequence of DNA. |
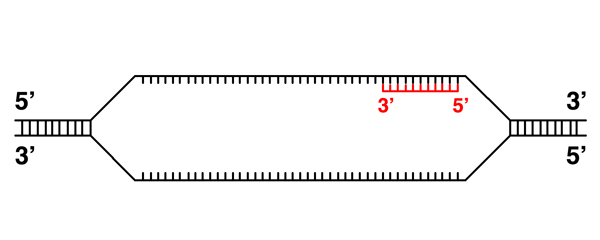 |
It is possible to transcribe the other strand in this example. |
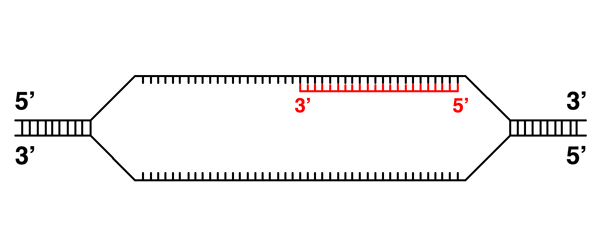 |
Here the RNA transcript continues elongation. |
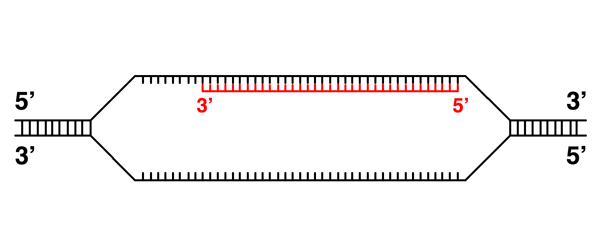 |
The transcript is complete. We know that only one strand of any gene is transcribed, so the transcription initiation and termination signals must be specific to one strand. |
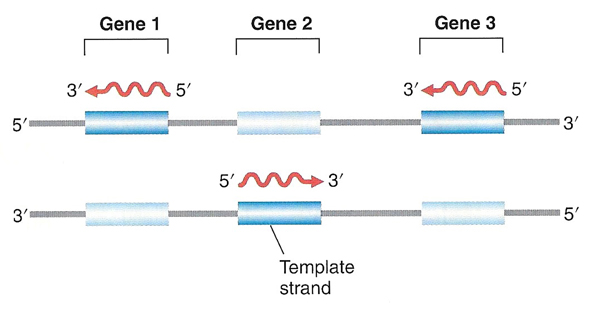 |
Because transcription start and stop signals are specific to one strand, different genes on the same chromosome can be oriented in different directions. Only one particular strand is ever transcribed for each gene. |
It is clear that base pairing between DNA and RNA is the basis for transcription. In addition, we can see that the proteins required for transcription must be able to bind to specific DNA sequences. What proteins are required for transcription, compared to DNA replication?
RNA polymerase. The enzyme that synthesizes the new RNA strand is called RNA polymerase. It must possess a 5' to 3' RNA polymerase activity. DNA polymerase has a 3' to 5' exonuclease activity that it uses for proofreading. RNA polymerase lacks a 3' to 5' exonuclease activity; there is less at stake in making an error in transcription than there is during DNA replication. DNA polymerase has a 5' to 3' exonuclease activity that it uses to remove RNA primers during the replication of the discontinuous strand. RNA polymerase lacks a 5' to 3' exonuclease activity; there is nothing ahead of the elongating RNA strand that needs to be removed. RNA polymerase is simpler than DNA polymerase because it lacks these two exonuclease activities.
Primase? DNA replication requires an RNA primer; initiating an RNA transcript does not require a separate primase. RNA polymerase is able to initiate transcription on a template lacking a primer.
Ligase? DNA replication requires ligase to join the Okazaki fragments on the discontinuous strand. RNA polymerase synthesizes a single strand continuously. Transcription does not require ligase.
Topoisomerase. Opening the DNA double helix for transcription induces supercoiling in the helix on either side, so topoisomerase is required for transcription.
The mechanism of transcription is obvious: base pairing between DNA and RNA allows the direct transfer of information from DNA to RNA. The mechanism of translation is not obvious. In the late 1950s, after the discovery of the secondary structure of DNA and the realization that a triplet code could be used to encode proteins, there was speculation about the mechanism of translation.
Some people thought that it might be possible to translate RNA directly, and that a three-base codon might form a kind of pocket that bound an amino acid.
Francis Crick thought that there was not enough information in three RNA bases to bind an amino acid directly, and proposed the existence of an adapter molecule. The adaptor would have to bind the triplet codon, so a nucleic acid adapter molecule was the obvious choice. The other end of the molecule would have to bind a specific amino acid. As it happens, Crick was right, and there are RNA adapter molecules that function in translation.
While all RNA is chemically similar, we can categorize RNA molecules into different classes based on their function. There are two broad categories of RNA. RNA molecules whose function is to encode proteins (mRNA) can be thought of as informational. RNA molecules that carries out a specific function without being translated into protein (rRNA, tRNA, and others) can be thought of as functional. The major types of RNA are described below.
mRNA. Messenger RNA (mRNA) encodes proteins. In eukaryotes, it exits the nucleus and is translated on ribosomes in the cytoplasm.
rRNA. Ribosomal RNA (rRNA) is a component of ribosomes. The key enzymatic activity of ribosomes, the formation of peptide bonds during protein synthesis, is not carried out by a protein, but rather by ribosomal RNA.
tRNA. Transfer RNAs (tRNA) are a class of RNA molecules that function as Crick's adaptor molecules during translation. One part of a tRNA recognizes a specific codon by base pairing. Another part of the tRNA is covalently bound to an amino acid that it contributes to the growing polypeptide chain during translation.
Other RNAs. There are other types of RNA that function in ribosomal assembly, mRNA processing, and gene regulation. These types all have specific names that are not important in a general introduction to gene expression.
In eukaryotes, there are multiple RNA polymerases that are specialized to carry out the synthesis of specific types of RNA. RNA polymerase I transcribes rRNA. RNA polymerase II transcribes mRNA. RNA polymerase III transcribes tRNA. Small RNAs required for ribosomal assembly and mRNA processing are transcribed by RNA polymerase II and RNA polymerase III, while other noncoding RNAs are transcribed by RNA polymerase III.
We know that there must be specific signals at the 5' end of a gene that mark it as a transcription start site. The DNA sequence that binds the transcription machinery is called the promoter. What do these signals look like? Comparison of the DNA sequences around the transcription start site of a set of genes from E. coli shows conserved elements, as shown in the figure below.
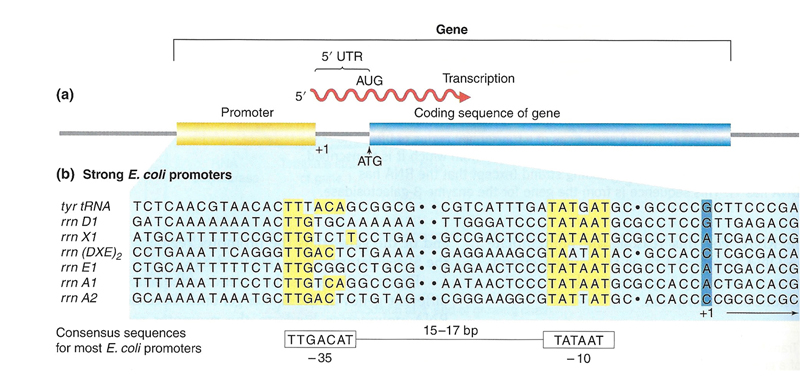
Note that the transcription start site does not exactly correspond to the codon that is used to initiate translation (ATG). Transcription begins upstream of this sequence. The RNA between the start of transcription (base 1) and the start of translation some distance downstream is called the 5' untranslated region or 5' UTR. There is also an untranslated region at the 3' end of an mRNA (3' UTR).
We can see from the sequence comparison in the figure that there are two conserved elements in promoter regions of e. coli: an element around -10 and an element around -35. These elements can be identified in most E. coli promoters.
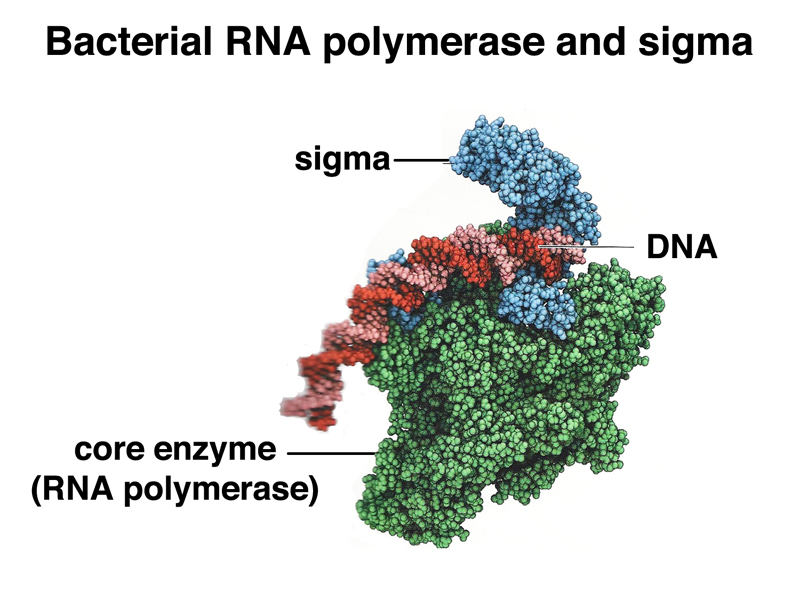
How does the transcription machinery recognize these sequences? RNA polymerase itself does not carry out recognition of the promoter. In E. coli, there is a separate protein called sigma factor that specifically recognizes the promoter. Sigma factor and RNA polymerase form a complex that initiates transcription at the promoter. Once RNA elongation has begun, sigma factor dissociates from the complex. The image below shows RNA polymerase, sigma factor, and DNA in a complex.
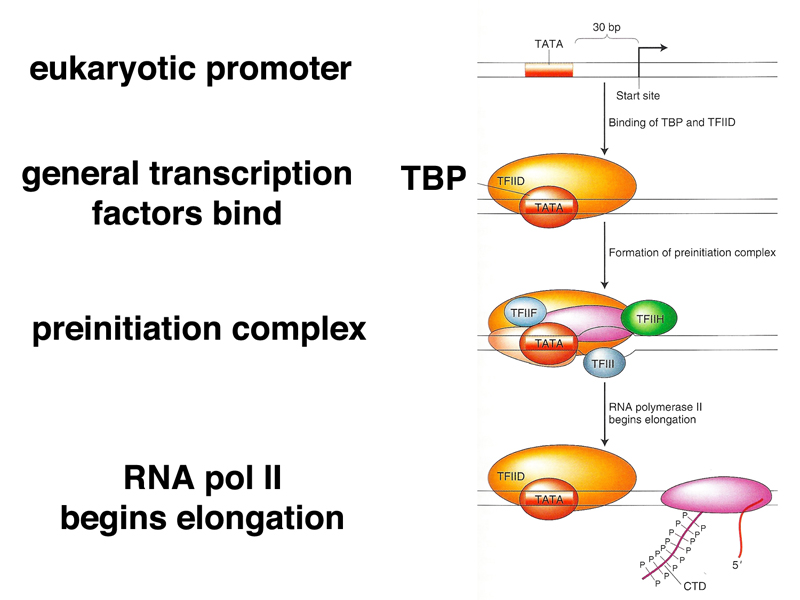
Initiation in eukaryotes is more complex. Most eukaryotic promoters have a "TATA box" at position -30, and typically have other classes of promoter sequences that are shared by groups of genes. While in bacteria, RNA polymerase and sigma factor are sufficient to initiate transcription, eukaryotes use a set of general transcription factors that bind to the promoter region, then recruit other protein factors including RNA polymerase. Once the preinitiation complex is formed, RNA polymerase is phosphorylated and released from the complex to begin RNA strand elongation. The process is shown in outline form below.
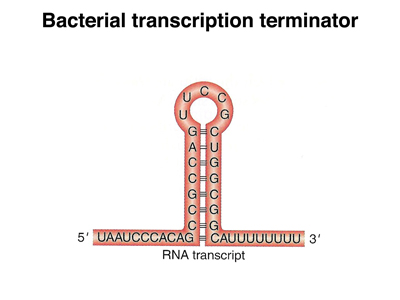
In E. coli, there are two mechanisms for transcription termination, an intrinsic mechanism and a mechanism that depends on a specific protein called rho factor. In the intrinsic mechanism, show below, there is a self-complementary sequence past the end of the coding sequence that forms a hairpin loop once it is transcribed. The base-paired part of the loop is very GC-rich, so the hairpin is stable. The presence of this structure seems to interfere with RNA eleongation, and transcription terminates.
 |
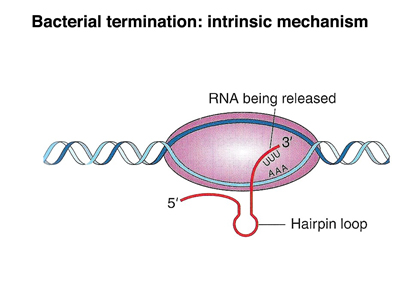 |
In rho-dependent transcription termination, a specific sequence at the end of the gene binds rho factor. When RNA polymerase encounters rho, the polymerase dissociates from the template, terminating transcription.
Eukaryotic transcription termination is similar to that of prokaryotes. We did not review any of the details.
In 1977, Phil Sharp hybridized an mRNA to its DNA template and prepared the hybrid molecule for electron microscopy by coating the nucleic acid with a basic protein, then using rotary shadowing to coat the nucleic acid-protein complex. The electron micrograph and an interpretative drawing are shown below.
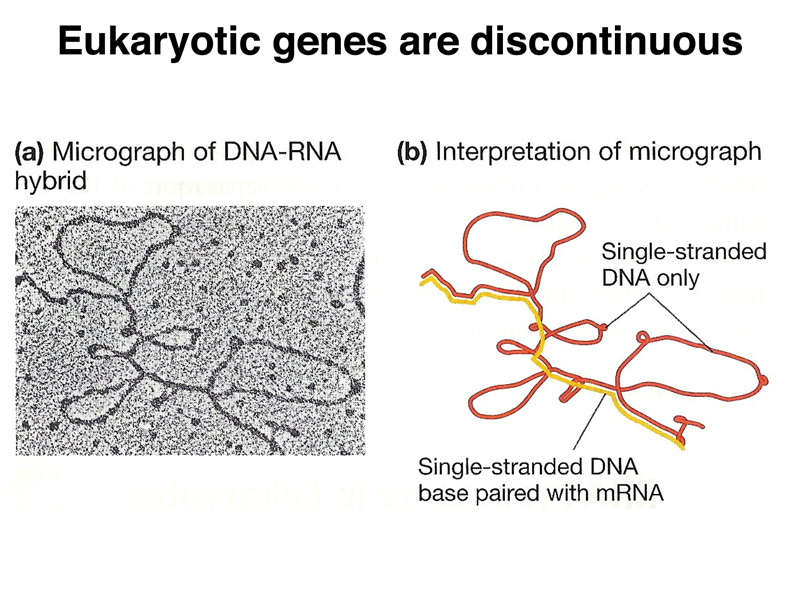
You can see that the transcript is discontiguous. There are parts of the DNA template that are not represented in the mRNA. Six such segments are visible.
When a eukaryotic gene is transcribed, the primary transcript is processed in the nucleus in several ways. The most striking modification, as shown in the photograph above, is splicing. Parts of the primary transcript, called introns, are spliced out of the mRNA. The remaining segments of mRNA are called exons. This process is shown in cartoon form below.
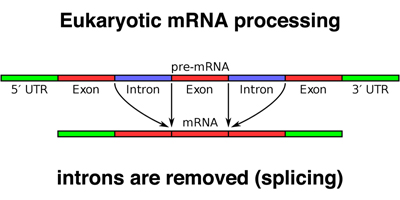
Sequencing of many eukaryotic genes reveals a consensus sequence for splice sites to remove introns, shown below.
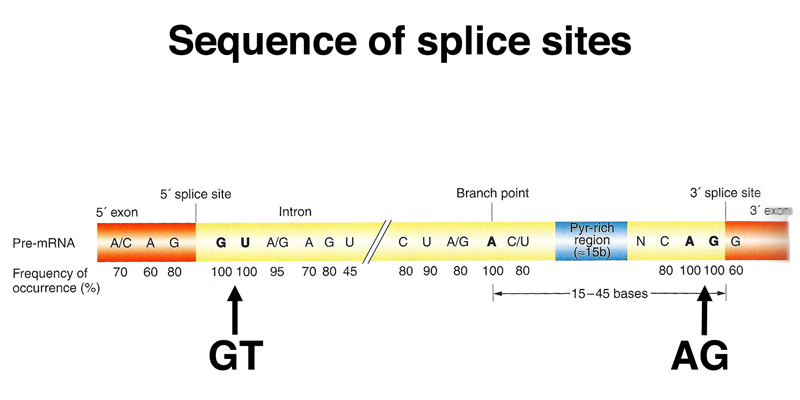
The 5' end of the intron begins with a splice donor site that almost always inclues GT as the first two bases of the intron (very rarely, it's GC). The 3' end of the intron ends with a splice acceptor site that always includes AG as the last two bases of the intron. Around the 5' GT and the 3' AG are short consensus sequences that allow us to identify likely splice sites in genomic DNA.
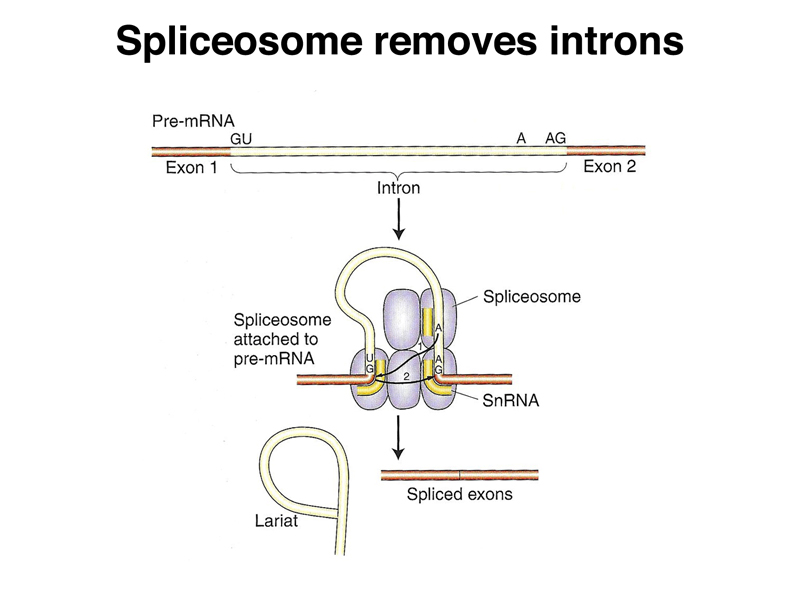
Splicing is facilitated by a ribonucleoprotein complex called the spliceosome. The spliceosome carries out the removal of introns as RNA lariats, joining exons together to make a mature mRNA, as shown below.
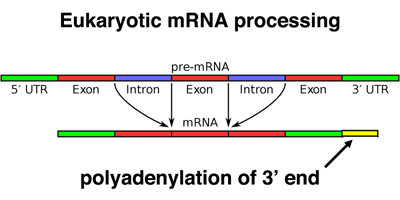
Eukaryotic mRNAs are also modified at the 3' end by the addition of a poly-A tail. This run of A residues is added by an enzyme that does not use genomic DNA as a template, as shown below.
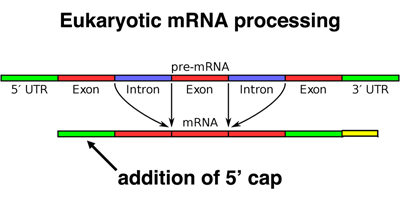
Finally, eukaryotic mRNAs have a chemical modification of the 5' end, called a cap. The cap is added to the first base of the 5' UTR, as shown below.
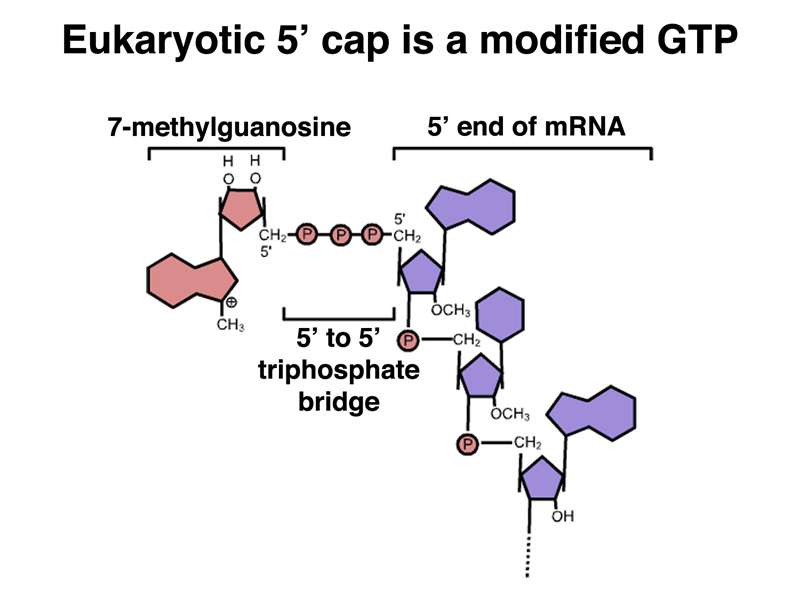
The cap is a 7-methylguanosine in a 5' to 5' phosphodiester linkage. The structure of the cap is shown below.
Splicing is regulated, with many genes producing multiple isoforms of the same protein that can differ considerably in their amino acid sequence due to alternative splicing. Isoforms of the muscle protein tropomyosin derived from alternative splicing are shown below. You can see that while there are some exons common to all isoforms, some isoforms have large protein segments entirely missing from other isoforms.
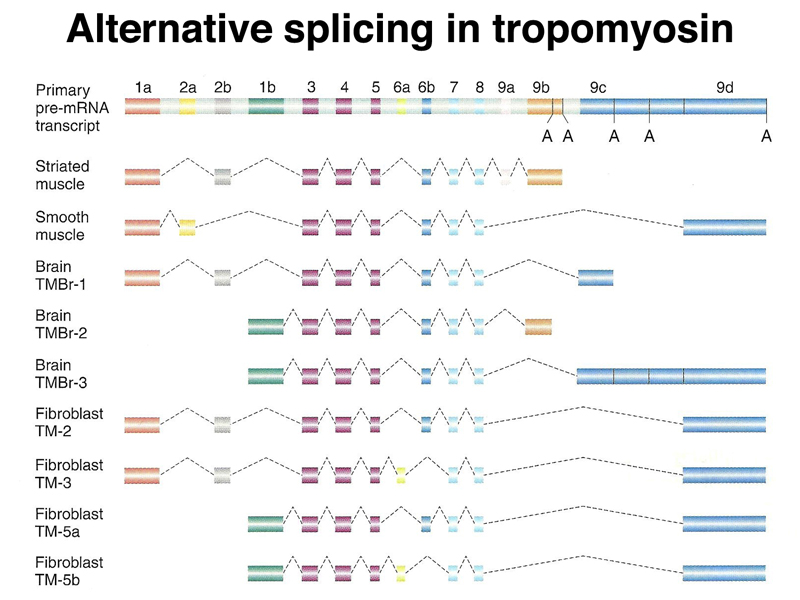
Now that we know about alternative splicing, we can see that Beadle and Tatum's rule of one gene, one enzyme, extended to mean one gene, one protein, is not entirely accurate. While the different protein isoforms encoded by a eukaryotic gene that shows alternative splicing are related and generally carry out the same function, it is actually possible for a gene to encode multiple proteins with different sequences and slightly different functions.