
| Home | Syllabus | Schedule | Lecture Notes | Extras | Glossary |
| Home | Syllabus | Schedule | Lecture Notes | Extras | Glossary |
We began by reminding everyone that the next exam is scheduled for Tuesday, October 15. I will post a study guide on Tuesday, October 8. Fall break is scheduled for Thursday and Friday, October 10 and 11. I will be available by apppointment on those days. I will not be here on October 14 or 15. Someone else will proctor the exam. Please schedule your study time with these things in mind.
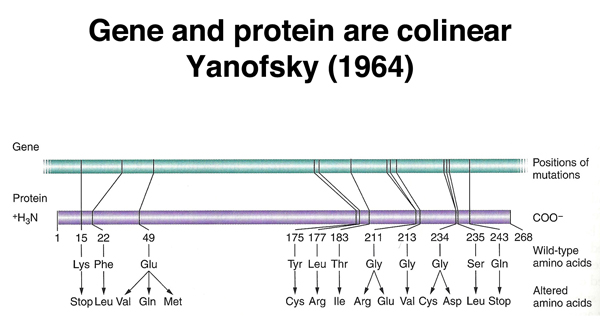
Our continued consideration of gene expression begins with the evidence that gene and protein are colinear. Charles Yanofsky showed this in the early 1960s by demonstrating that the positions of mutations in a gene required for tryptophan metabolism in E. coil, as determined by genetic mapping, corresponded to their positions of the amino acid substitutions in the protein, as determined by protein sequencing. The demonstration of the colinearity of gene and protein suggested that the mechanism of translation of a nucleic acid sequence into a protein was likely to be easy to understand.
We also reviewed the evidence, presented in the last lecture, that there was an RNA intermediate between DNA and protein. If eukaryotic cells are giving a pulse of labeled uridine (for example, five minutes), followed by a chase with cold uracil, the labeled uracil is first seen in the nucleus. At later time points, the uracil is seen in the cytoplasm.
Similar experiments with labeled amino acids demonstrate that proteins are synthesized in the cytoplasm. Because DNA does not leave the nucleus, this suggests that the information in DNA leaves the nucleus as RNA to be translated into protein in the cytoplasm.
We also reviewed the three important classes on RNA from last time: messenger RNA or mRNA, which encodes proteins; transfer RNA or tRNA, the adapter molecule used in translation; and ribosomal RNA or rRNA, a component of ribosomes.
In 1960, Francis Crick noted the evidence that protein synthesis was directed by an RNA intermediate. He also knew that almost all of the RNA in a cell was in ribosomes. This led him to propose that each ribosome carried an RNA copy of a specific gene, and synthesized a single protein. This was the "one gene, one ribosome, one protein" hypothesis.
In 1961, Brenner, Jacob, and Meselson carried out an experiment that tested this hypothesis. They were already somewhat skeptical of the "one gene, one ribosome, one protein" hypothesis, because the RNA isolated from ribosomes was more homogeneous than would be expected if each ribosome carried the RNA copy of a single gene.
Brenner, Jacob, and Meselson used E. coli and bacteriophage T2 for their experiment. This was a terrific experimental system, because when T2 infects E. coli, all bacterial protein synthesis stops; only phage protein is synthesized. An early protein product of phage infection destroys the bacterial chromosome, making bacterial gene expression impossible.
Their experiment is outlined below.
| Brenner, Jacob, and Meselson (1961) | |
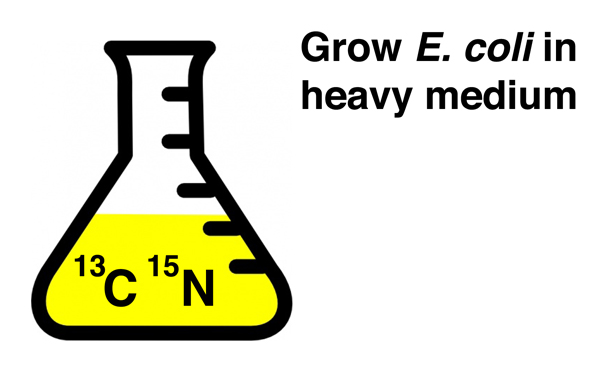 |
They began by growing E. coli for several generations in culture medium containing heavy isotopes of carbon (13C) and nitrogen (15N) to incorporate a density label into all components of the bacterial cells, including ribosomes. |
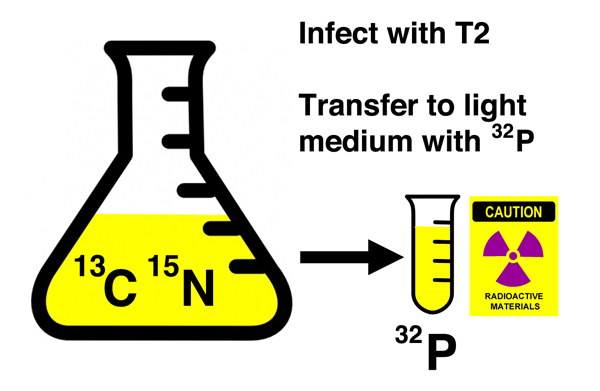 |
Then they infected the density-labeled cells with phage T2 and immediately transferred a portion of the culture to "light" medium containing 32P. As you recall from our discussion of the Hershey-Chase experiment, 32P will radioactively label nucleic acids (DNA and RNA), but not protein. |
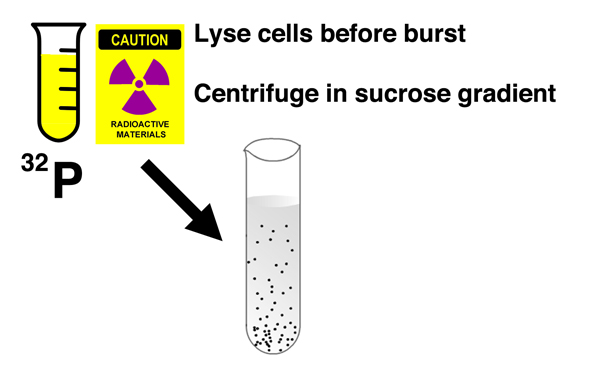 |
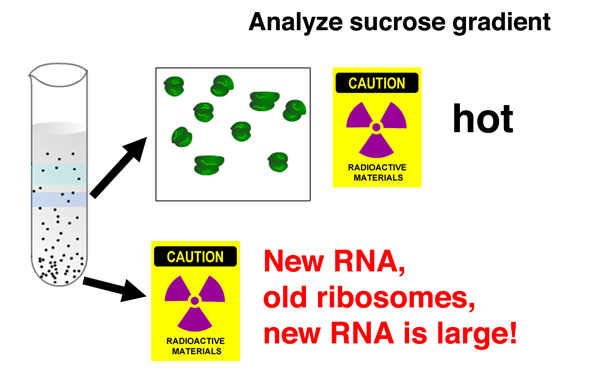
After incubating the cells in light medium with 32P for several minutes, they burst the bacterial cells before phage lysis could occur and centrifuged the cell lysates in a sucrose gradient. A sucrose gradient is a density gradient produced by slowly layering a solution containing a decreasing concentration of sucrose in a centrifuge tube. Components of the cell lysate will either pellet to the bottom of the tube, or reach a position in the gradient that is a function of their shape and mass. |
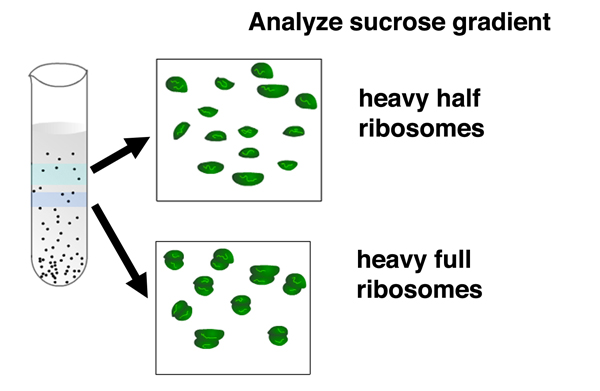 |
After centrifugation, the gradient is fractionated by punching a hole in the bottom of the tube and collecting fractions. There are two distinct fractions containing ribosomes: a fraction that sediments more slowly containing separate large and small ribosomal subunits, and a fraction that sediments more quickly containing complete ribosomes. Both fractions contain only heavy ribosomes with the density label. There are no light ribosomes. |
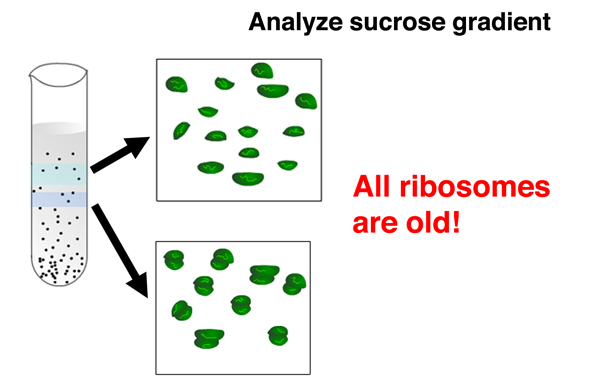 |
The absence of light ribosomes shows that phage infection does not cause the synthesis of new ribosomes. All ribosomes in cells that have undergone phage infection are old. This shows that old ribosomes that were making bacterial proteins are used to make phage proteins, and that the "one gene, one ribosome, one protein" hypothesis is incorrect. |
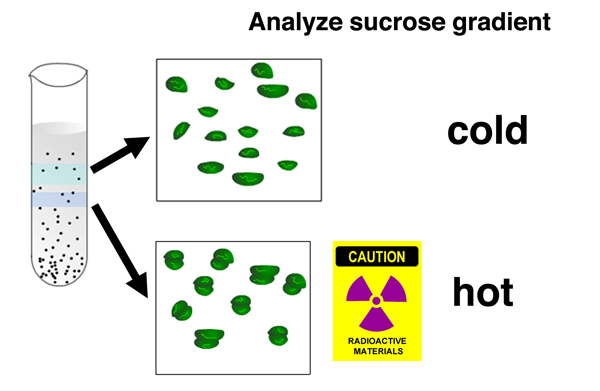 |
Analysis of the location of 32P in the gradient shows that there is no newly-synthesized nucleic acid associated with separated ribosomal subunits, but there is newly-synthesized nucleic acid associated with complete ribosomes. |
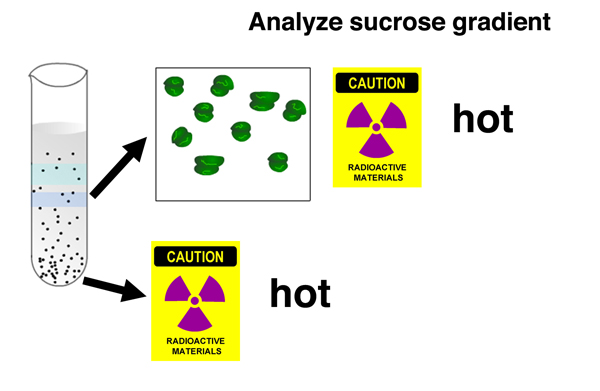 |
In addition, there is 32P associated with a fast-sedimenting nucleic acid recovered from the bottom of the gradient. The newly-synthesied nucleic acid is a large molecule. |
 |
It was known that there is a burst of RNA synthesis associated with phage infection. Together, these results show that newly-synthesized RNA associates with old ribosomes during pahge infection. The newly-synthesized RNA is a large molecule. |
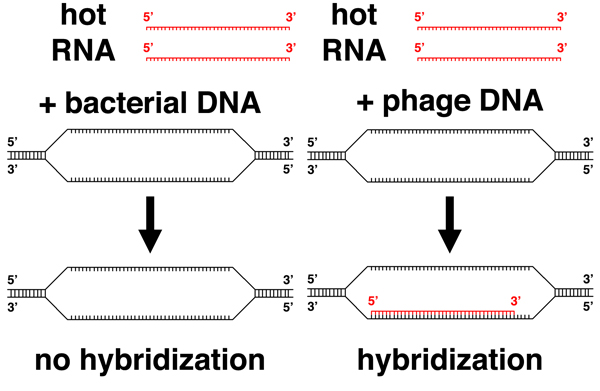 |
They went on to show that the labeled RNA resulting from phage infection did not hybridize to bacterial DNA, but hybridized to phage DNA, showing that the RNA molecules produced upon phage infection are transcribed from the phage genome. |
This experiment showed that phage infection causes RNA synthesis but not ribosome synthesis. It demonstrated the existence of a minor class of RNA, messenger RNA (mRNA), an informational molecule copied from the phage genome to direct the synthesis of phage proteins. It also showed that ribosomes are general purpose machines for translation. Individual ribosomes are not specialized to make a specific protein.
We concluded that although Crick was wrong in his formulation of the "one gene, one ribosome, one protein" hypothesis, the secret to having good ideas is to have a lot of ideas and throw away the bad ones. Crick's hypothesis was not exactly a bad idea. In his defense, 95% of the RNA in a cell is ribosomal RNA and tRNA; only 5% of the RNA is mRNA.
Before we get into all of the details of translation, it is worth gaining an overview of transcription and translation in prokaryotes and eukaryotes. As shown below, transcription and translation are coupled in prokaryotes: translation of mRNA begins before the molecule has completed synthesis. This make it apparant that translation proceeds from the 5' end of the mRNA (the first part to be synthesized) to the 3' end. In eukaryotes, the primary transcript is processed into mRNA in the nucleus via splicing, capping, and polyadenylation before export to the cytoplasm for translation.
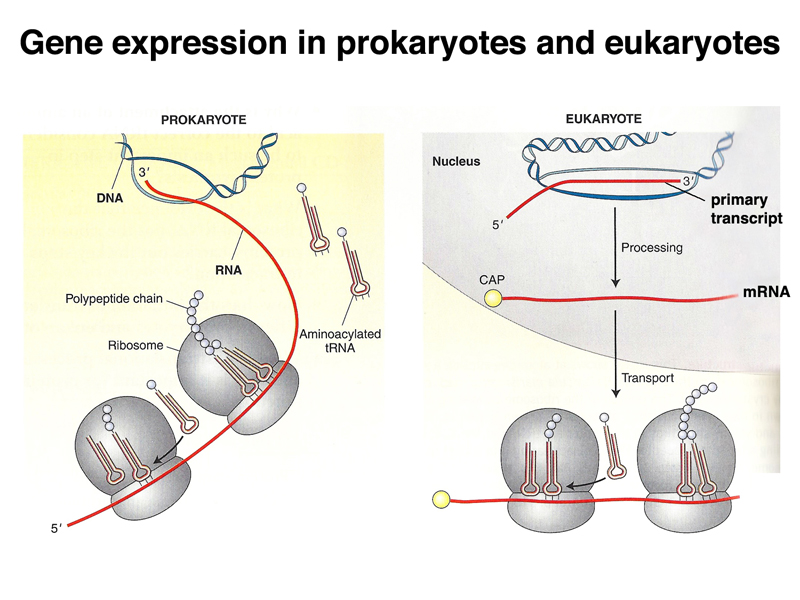
The image below shows the coupling of transcription and translation in bacteria, both in an electron micrograph and in a cartoon interpreting the image.
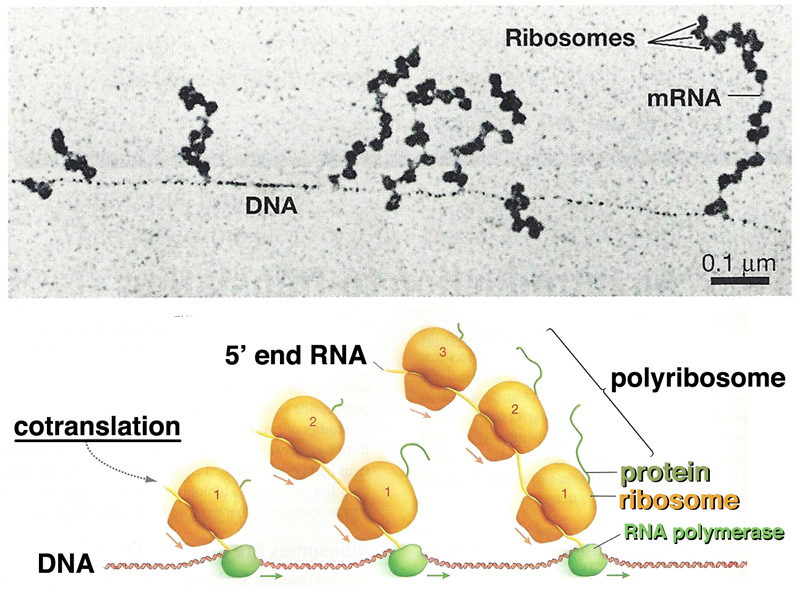
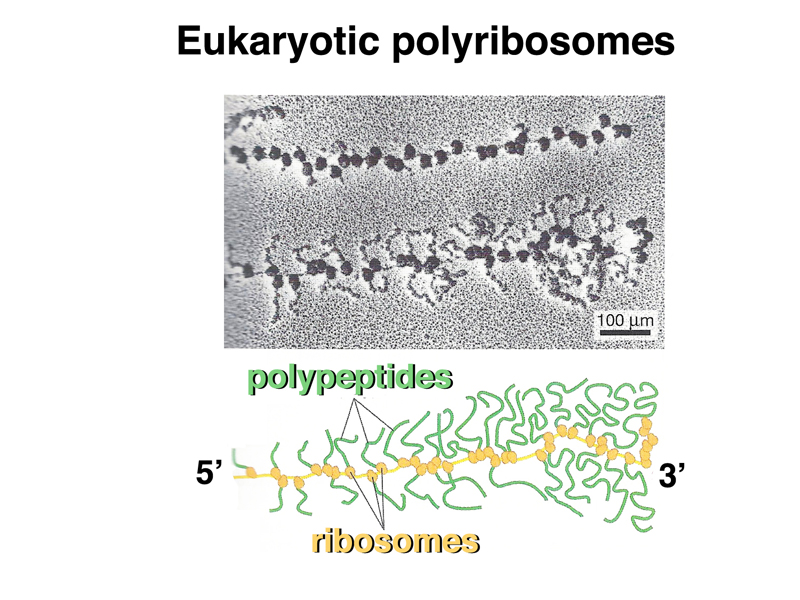
The image below shows eukaryotic polyribosomes in an electron micrograph and in a cartoon. In this case, you can see the newly-synthesized peptide, and can tell which is the 5' end of the mRNA, because there are shorter protein tails on the ribosomes at that end.
We began our discussion of trnasfer RNA by reviewing our discussion of the genetic code. We know from experiments discussed in previous lectures that the genetic code is a triplet code in which 64 three-base codons represent the 20 primary amino acids as well as a start and stop signals. We also know that the genetic code is nonoverlapping and lacks punctuation between codons.
Early discussions of the mechanism of translation of the genetic code into an amino acid sequence produced two hypotheses: one in which the triplets somehow bound to amino acdis directly, and the other, advanced by Francis Crick, in which there was an adapter molecule (presumably a nucleic acid) between codons and amino acids.
The first evidence for the adapter molecule came from Zamecnik. In 1958, he developed the first cell-free system for protein synthesis. A few years later, he observed that there was a specific RNA fraction that became labeled with 14C-amino acids. Following that observation, other researchers verified that there were small RNA molecules required for translation that became covalently attached to amino acids. The structure of these molecules, called transfer RNA or tRNA, was also soon determined. We review the structure of tRNAs below.
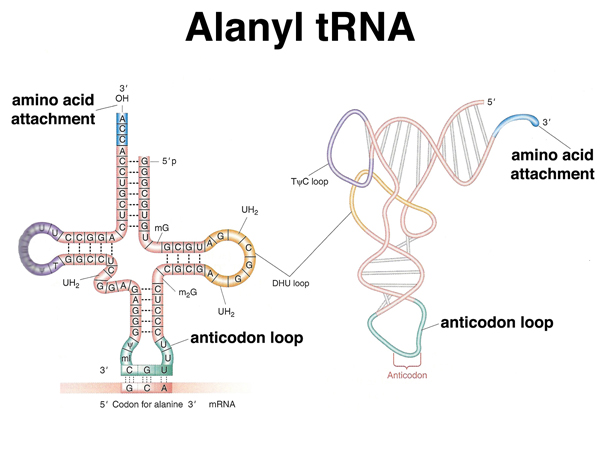 |
A transfer RNA has a cloverleaf structure with regions of base pairing. A tRNA has the structure shown here both as a flat cloverleaf and in its folded form. There are two very important parts of a tRNA: the anticodon, which participates in base pairing with a codon in the mRNA, and the site of amino acid attachment at the 3' end of the tRNA. |
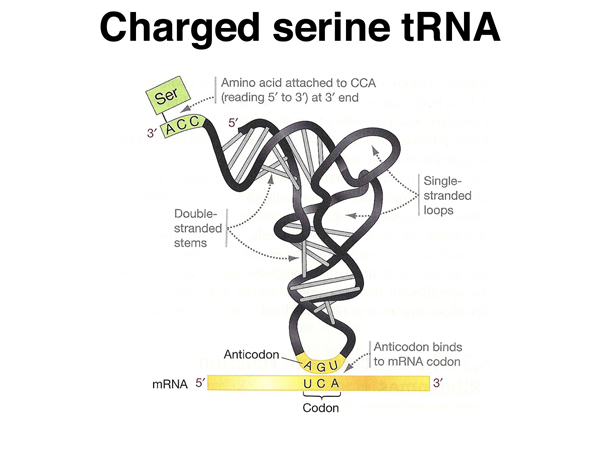 |
This shows a "charged" serine tRNA, covalently attached to the amino acid serine at its 3' end, with the anticodon paired to a serine codon. |
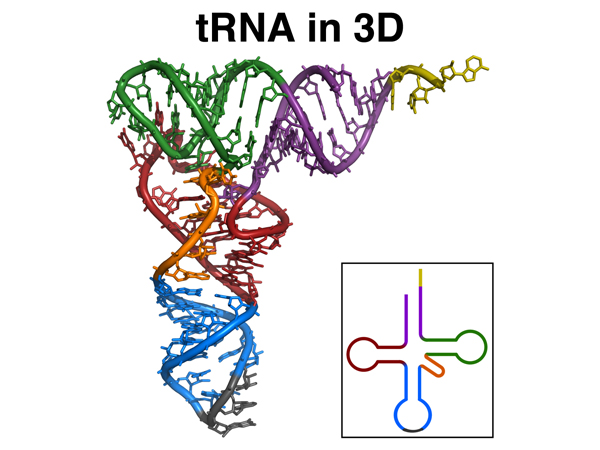 |
This is a better representation of the 3D structure of a tRNA. The model is color-coded to the flat cloverleaf representation in the lower right. |
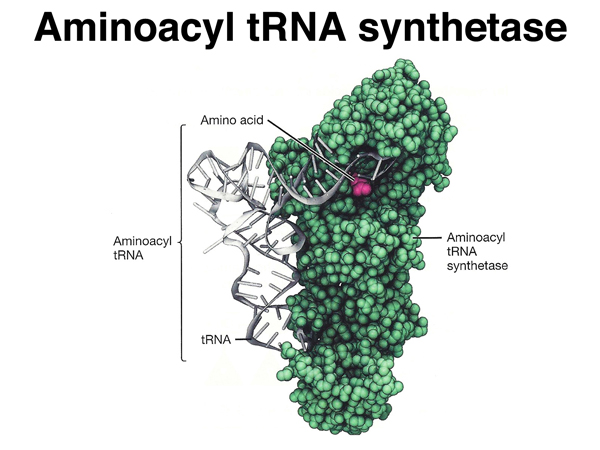 |
A special set of enzymes "charges" tRNAs, attaching the correct amino acid to particular tRNAs.
A charged tRNA is called an aminoacyl tRNA, so the charging enzymes are more properly called
aminoacyl tRNA synthetases. There is only one aminoacyl tRNA synthetase for each amino acid, even
though there can be multiple tRNAs for that amino acid. Each aminoacyl tRNA synthetase is able to recognize
all of the tRNAs that need to be charged with the one amino acid that is their specialty.
Amino acids are attached to the hydroxyl (-OH) group at the 3' end of the tRNA through their carboxyl (-COOH) group. |
Now that we know about rRNA, mRNA, and tRNA, we are ready to look at the process of translation in detail, as shown below.
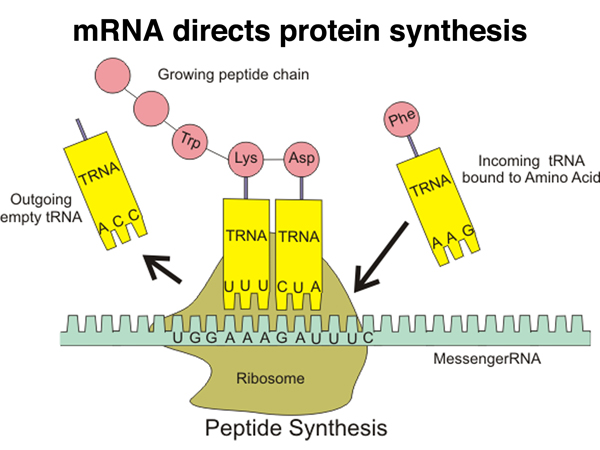 |
This cartoon gives an overview of translation. Proteins are synthesized by ribosomes that read the sequence of mRNA and write it as protein. Translation is accomplished with the help of charged tRNAs that allow individual codons to specify the next amino acid added to the growing polypeptide. The mRNA, as we have seen, is read from the 5' end to the 3' end, with the protein being synthesized from the amino terminus to the carboxy terminus. |
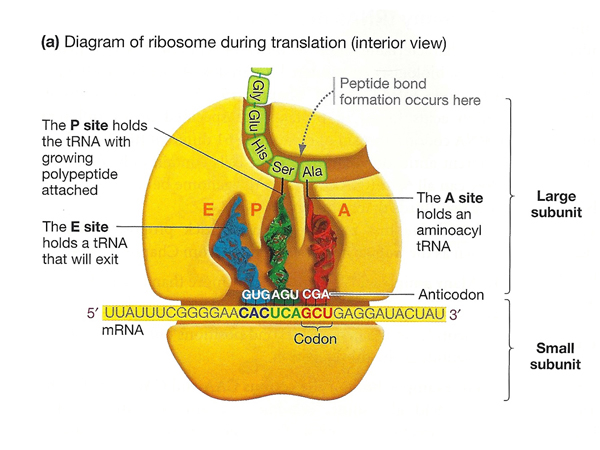 |
Here is a more detailed cartoon of the ribosome during translation, identifying three sites associated with tRNAs: the A (aminocyl) site, that accepts a new aminoacyl tRNA; the P (polypeptide) site, that holds a tRNA with the growing polypeptide chain; and the E (exit) site that holds an uncharged tRNA ready to exit the ribosome. |
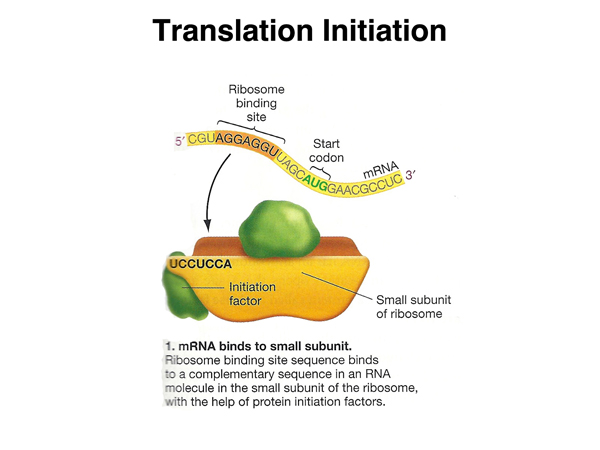 |
Translation is initiated when an mRNA molecule, which has a ribosome-binding site in its 5' UTR, binds the complementary sequence in the rRNA molecule that is part of the small ribosomal subunit, with the help of initiation factor proteins. |
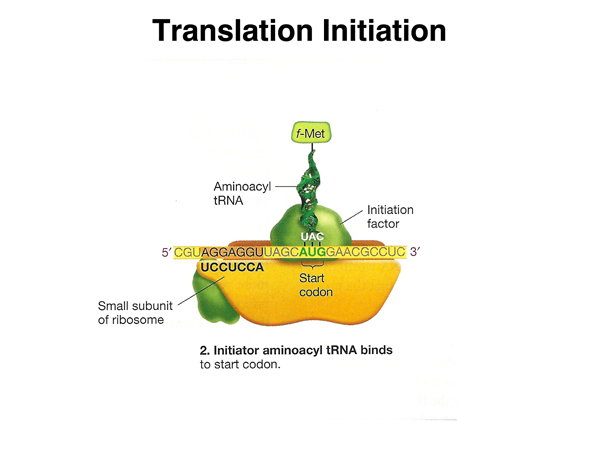 |
Another initiation factor assists in the binding of a charged tRNA molecule to the start codon. This tRNA is N-formylmethionine in bacteria (the formyl group is later removed) and methionine in eukaryotes. |
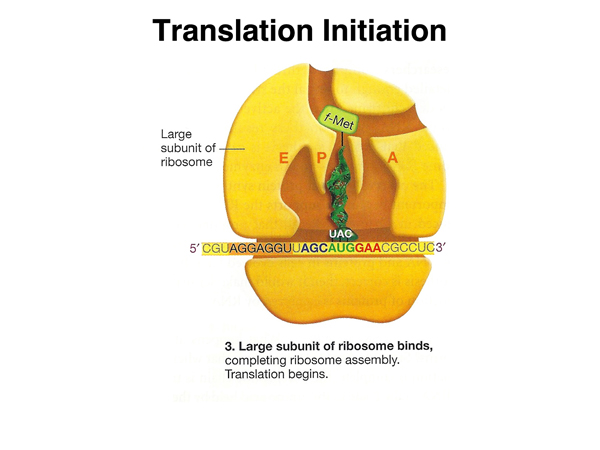 |
The large ribosomal subunit binds, with the initiatior tRNA in the P site. |
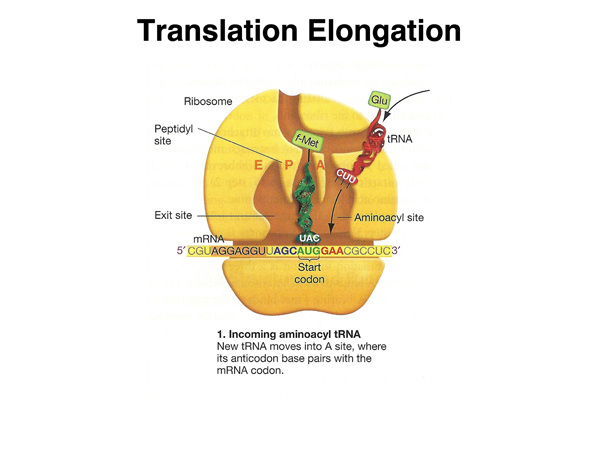 |
Elongation begins when the next aminoacyl tRNA occupies the aminoacyl (A) site. The amino acid shown here is glutamic acid, but any amino acid can be the second amino acid specified by a particular mRNA. |
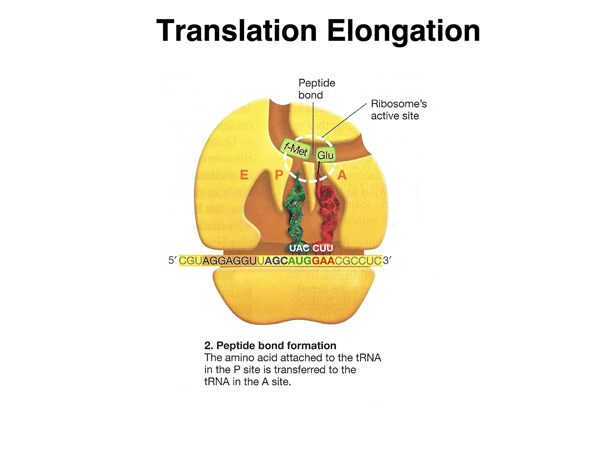 |
The peptidyltransferase center in the large subunit catalyzes the formation of a peptide bond bewteen the amino acid in the P site and the amino acid in the A site. This reaction is catalyzed by ribosomal RNA (a ribozyme) rather than by a protein enzyme. |
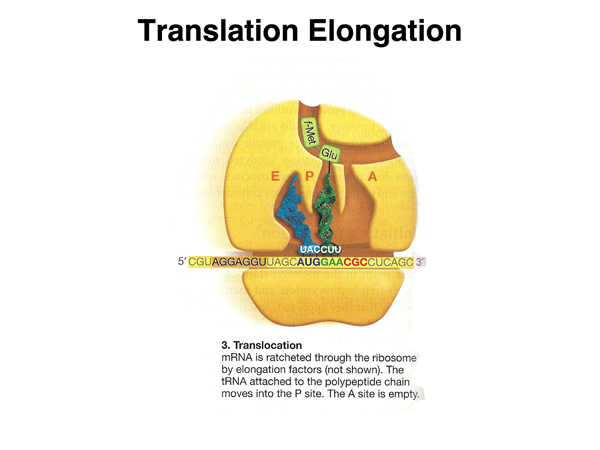 |
Once the peptide bond is formed, the mRNA is moved through the ribosome to place the tRNA with the growing peptide chain in the peptidyl (P) site. |
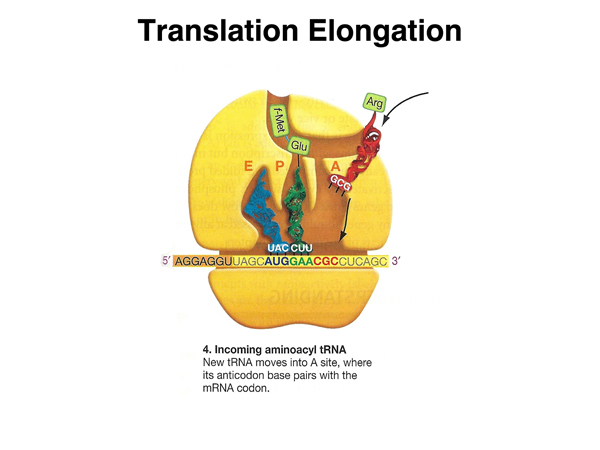 |
A new aminoacyl tRNA is then free to occupy the aminoacyl site. |
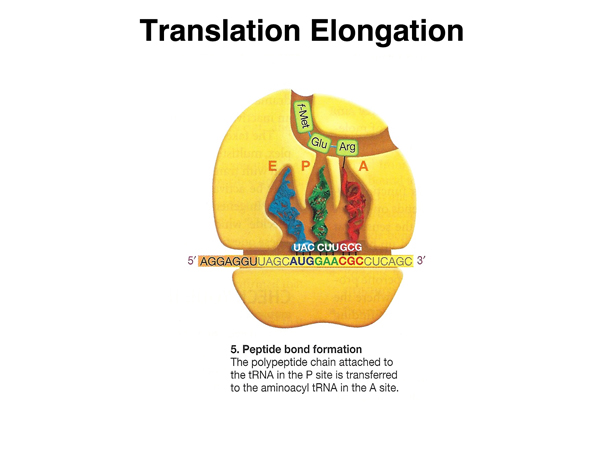 |
The next peptide bond is synthesized. |
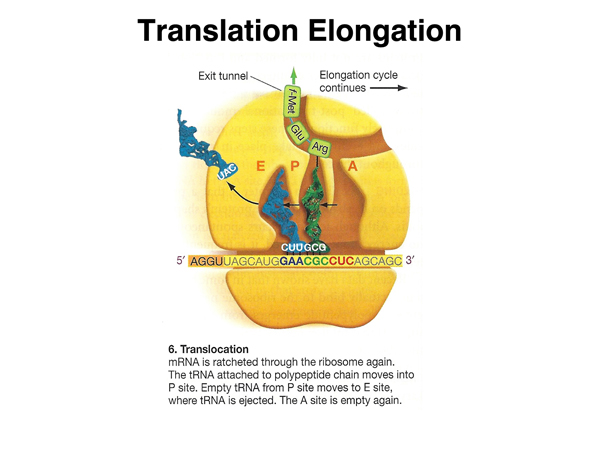 |
The mRNA is moved again, to place the tRNA with the growing peptide chain in the peptidyl (P) site. |
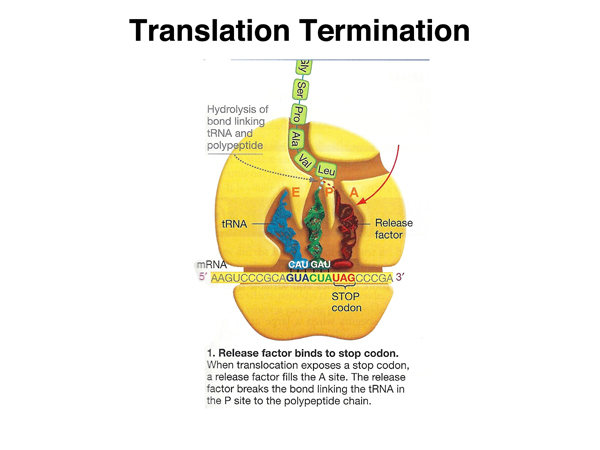 |
When the stop codon is reached, a release factor protein whose structure resembles that of a tRNA enters the A site. |
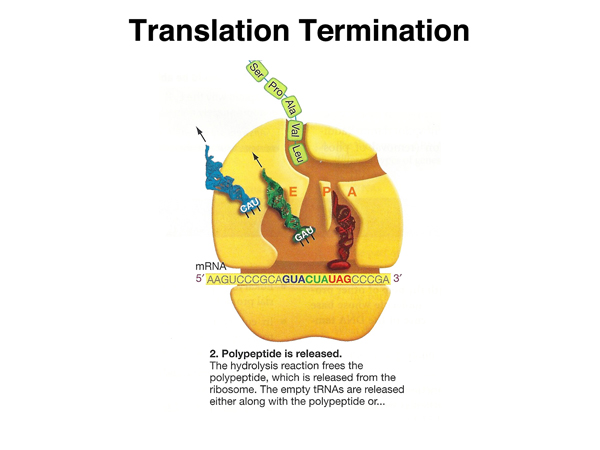 |
Hydrolysis of the bond between the aminoacyl tRNA and the carboxy terminus of the last amino acid releases the peptide. The tRNAs are also released. |
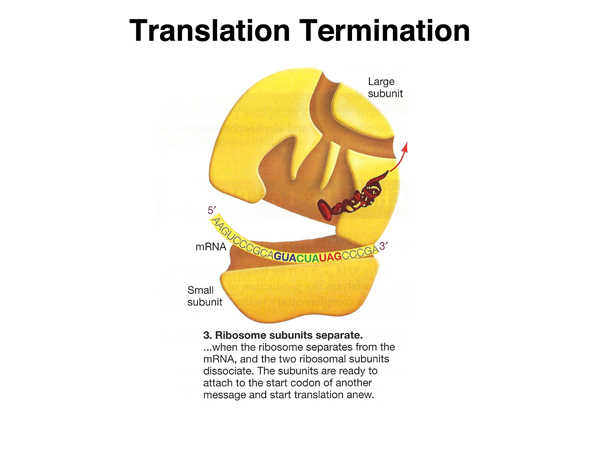 |
The ribosome separates from the mRNA and the two subunits of the ribosome dissociate. |
In 1961, Marshall Nirenberg and Heinrich J. Matthaei at the National Institutes of Health were able to use synthetic RNAs to direct the synthesis of protein in a cell-free system. They added poly-U to twenty different reactions, each containing a mix of all twenty amino acids with a specific amino acid labeled. Following the reaction, proteins were precipitated in a way that does not precipitate amino acids, and the precipitate assayed for radioactivity. They found that poly-U directed the synthesis of polyphenylalanine, meaning that UUU is a phenylalanine codon. They found that poly-A directed the synthesis of polylysine and poly-C directed the synthesis of polyproline.
Subsequent work used copolymers of ribonucleotides with specific ratios of bases (e.g. U:A = 2:1). Eventually, other researchers developed the technique to synthesize RNAs of known sequence and improved assays for which amino acid was associated with a particular codon. The complete genetic code became known in 1966.
The genetic code is shown below.
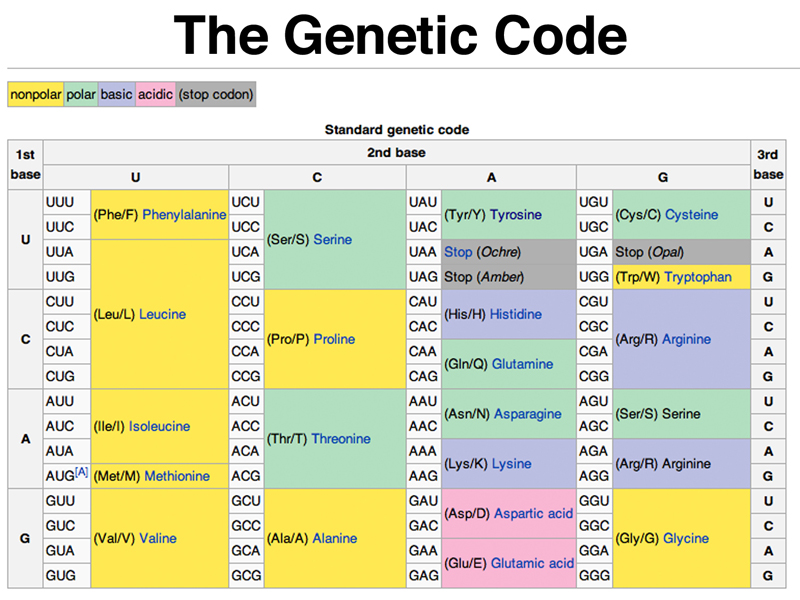
There are several things evident about the genetic code when this table is studied. The first thing to note is that groups of synonymous codons often differ only in their third base position. For example, all four CUX codons encode leucine, while all four CCX codons encode proline.
You can also see that there is a single start codon (AUG) and three stop codons (UAA, UAG, and UGA).
Most species have fewer than 45 types of tRNA, rather than the 61 necessary to recognize each codon by exact base pairing. The "wobble hypothesis" proposes that there are relaxed rules for base pairing with the third base of a codon. Some tRNAs have inosine as a base in this position. Inosine can pair with A, C, or U. In the third position, G can pair not only normally with C, but also with U. In the third position, U can pair not only with A, but also with G.
The other thing to notice about the code is that it is fairly well buffered to mitigate the effects of base substitution mutations. In many cases, substitution of a base, especially at the third base position of a codon, is often a synonymous substitution that does not change the amino acid encoded. In other cases, single base substitutions are likely to result in the substitution of a chemically similar amino acid, for example leucine for isoleucine (both nonpolar) or serine for threonine (both polar). Theoretical work shows that the universal genetic code is more buffered against the effect of mutation then are thousands of codes generated randomly, suggesting that the universal genetic code is optimal.
Now that we know how transcription and translation work, we are ready to review the parts of a eukaryotic gene as preparation for our discussion of mutation.
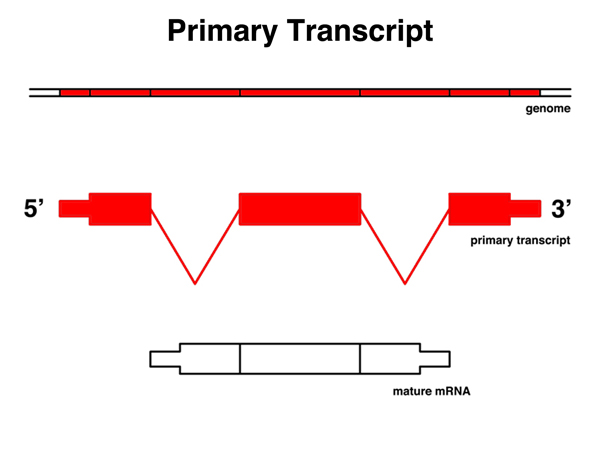 |
The primary transcript is the RNA copy of a gene before any splicing, polyadenylation, or the addition of the 5' cap. It is a copy of a contiguous protion of the genome. Parts of the primary transcript are present in the mature mRNA. |
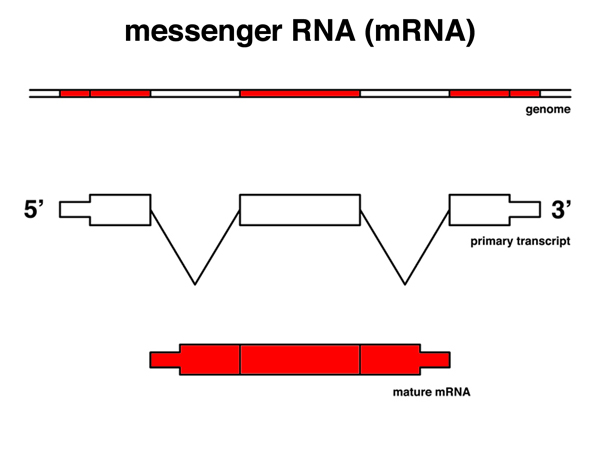 |
The messenger RNA or mRNA is the molecule that is sent to the cytoplasm for translation. It has been spliced, polyadenylated, and capped. For genes that are spliced, the sequence of the mRNA (except for the polyA tail) matches discontiguous segments of the genome. |
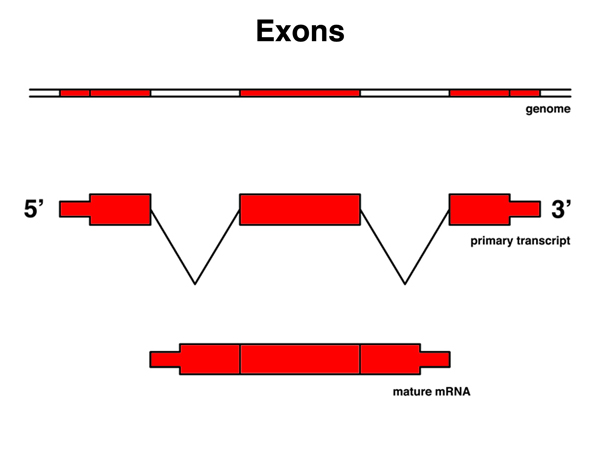 |
Exons are those portions of the primary transcript that are retained in the mRNA. |
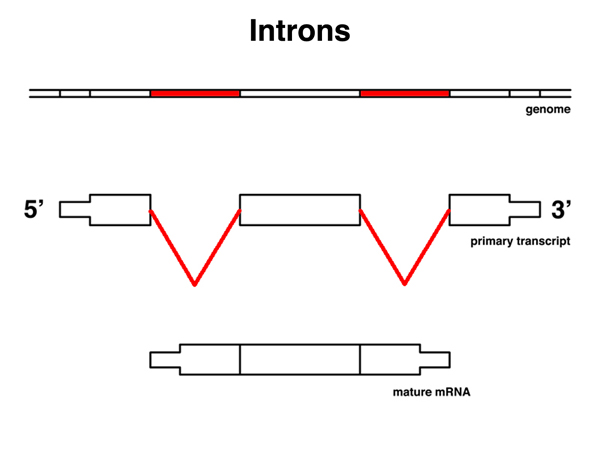 |
Introns are those portions of the primary transcript that are not retained in the mRNA. |
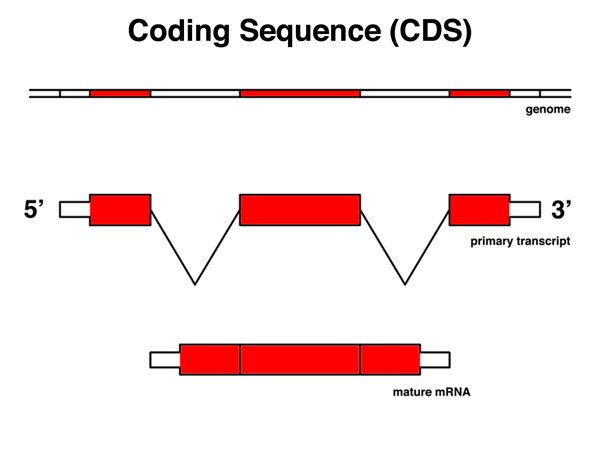 |
The coding sequence or CDS is that part of the mRNA that is translated, from the AUG start codon to the last codon before the stop codon. |
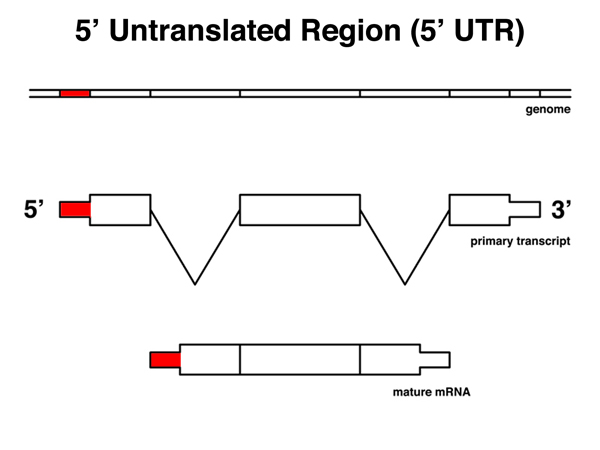 |
The 5' untranslated region or 5' UTR is that part of the mRNA from the 5' end to the last base before the AUG start codon. The 5'UTR includes the ribosome binding site. |
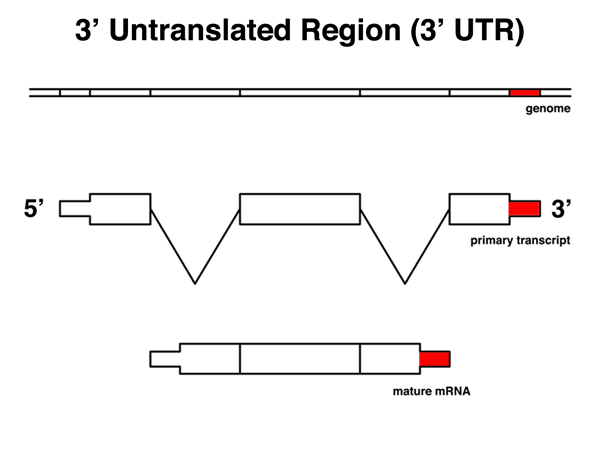 |
The 3' untranslated region or 3' UTR is that part of the mRNA from the stop codon to the 3' end of the mRNA, excluding the polyA tail. The 3' UTR includes a polyadenylation signal. |